What the PAVA Framework engagement looks like in advisory-led high-trust categories.
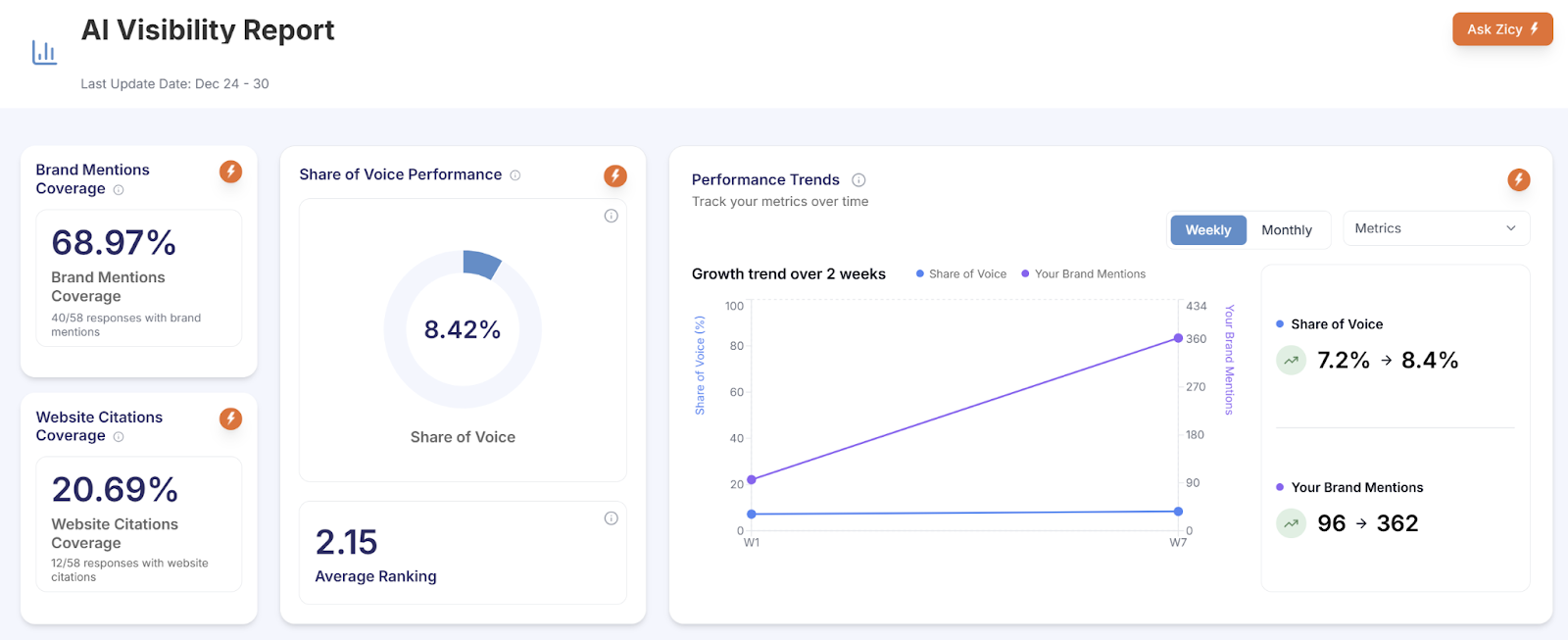
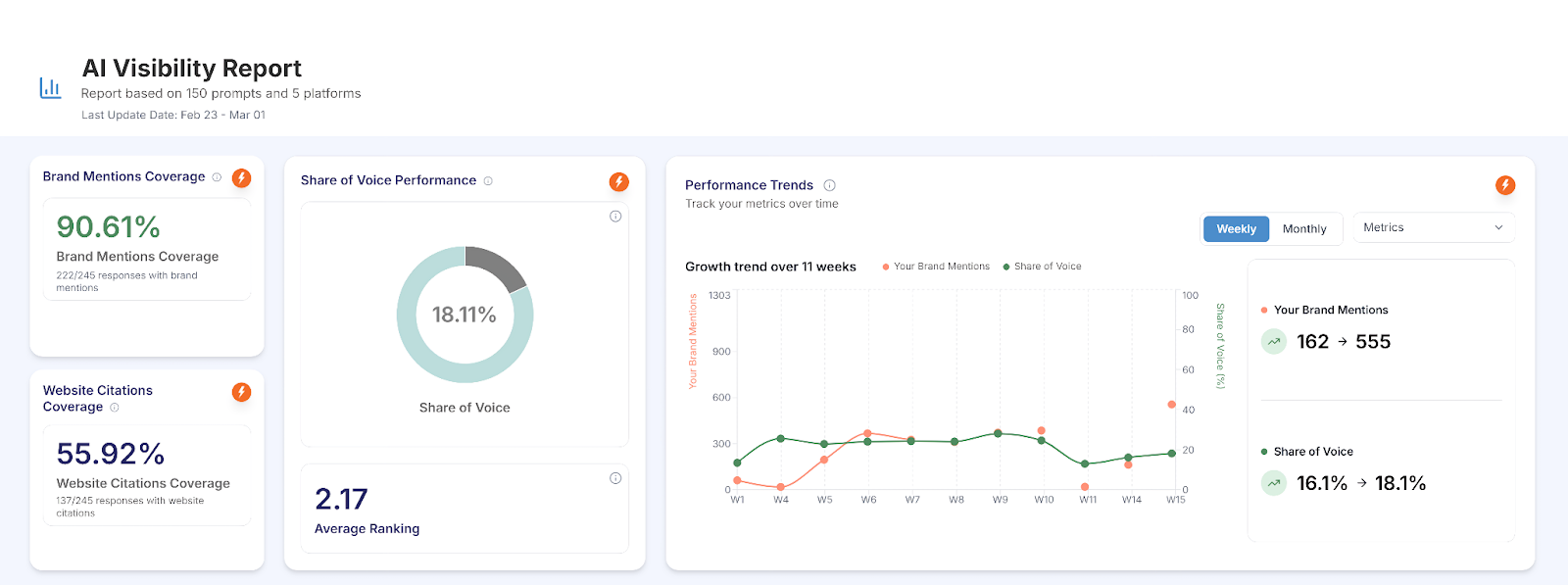
A B2B advisory client engaged us with a clear question. In a high-trust category where credibility is currency, how consistently was the brand being mentioned, cited, and ranked inside AI answers? Over the engagement window, mention coverage reached 90.61% across 150 tracked prompts and five AI platforms. Share of voice held the top position against five direct competitors at 18.11%.
Below is what the work involved, and what I would take from it.
The Starting Position
In advisory-led B2B categories, credibility used to be shaped by trade-publication coverage, conference visibility, and the quality of the practitioner’s publishing record. Those signals still matter. They are also no longer the only signals shaping how buyers form their initial view of a brand. AI platforms have absorbed a large share of the early-stage advisory-shopping conversation, and the brand that appears repeatedly across multiple platforms becomes the perceived category leader.
That dynamic was already running around this client before we engaged. The brand had an established advisory practice with healthy direct-referral pipeline. The question was whether the AI layer was supporting that practice or quietly favouring competitors.
We baselined the brand across ChatGPT, Gemini, Perplexity, Google AI Overviews, and Google AI Mode. We mapped 150 advisory-stage and category-defining prompts the buyers actually run. We benchmarked against five direct competitors.
The baseline was already strong on some dimensions. The work was about lifting consistency across the full set, not creating presence from zero.
The engagement ran across all four pillars of the PAVA Framework: Presence, Authority, Visibility, Amplification. Each pillar addresses a question AI platforms appear to weigh before deciding whether to surface a brand in an answer.
-
PRESENCE. Entity integrity.
Brand-service association signals were tightened across the site. Ambiguous phrasing that was diluting AI citation likelihood was removed. Explanations were restructured into the patterns AI summarisation tends to extract cleanly. Schema deployment audited and refreshed. Canonical brand description aligned across LinkedIn, Crunchbase, and the relevant industry directories. Wikipedia work went through the standard contributor process with paid-contributor disclosure where the policy requires it.
-
AUTHORITY. Earned editorial standing.
We mapped the third-party publications AI platforms actually cite in this advisory category. Trade publications, analyst coverage, and category-defining outlets. We briefed the brand’s existing PR partner against that target list with angle briefs aligned to genuine editorial opportunities the firm could pursue on the merits of the work. Citation outcomes were measured against each placement.
This is what AI Citation Enablement looks like on the earned side. AICE is the discipline we run across all four PAVA pillars: making the brand’s expertise easier for AI to find, verify, and accurately attribute, on the brand’s own merits.
-
VISIBILITY. Content architecture.
We mapped the prompt universe, our term for the 150 high-intent advisory and comparison queries the brand’s buyers actually run on AI platforms. Comparison queries and category-defining “best provider” prompts were prioritised. Owned content was restructured into the formats AI retrieval systems extract most reliably: direct answers at the top of advisory pages, comparison tables for evaluation-stage queries, named methodology frameworks for the brand’s advisory approach, and statistics sourced with publisher, sample, and year.

-
AMPLIFICATION. Sustained presence.
This pillar carried unusual weight on this engagement. Continuous monitoring across all five named AI platforms. Weekly share-of-voice movement tracking against the five-competitor set. Ranking and citation deltas used to validate adjustments. The focus was deliberately on consistency rather than spikes, because AI appears to weight stable citation patterns over time as a credibility signal.
Across the 11-week tracking window, share of voice moved from 16.1% to 18.1%. The trajectory was stable upward, not punctuated by one-off jumps. That is the shape of compounding in this work, and it is the shape that holds.
The Numbers
By the end of the engagement, across 150 tracked prompts and five platforms:
- Brand mention coverage: 90.61% (222 of 245 AI responses)
- Citation rate: 55.92% (137 of 245 responses)
- Share of voice: 18.11% (highest among five competitors)
- Average AI ranking position: 2.17
- 11-week share-of-voice movement: 16.1% → 18.1%
- Trajectory: stable upward, not spike-driven

We measure outcomes against what we call the M-C-R stack: Mention, Citation, Recommendation. This engagement is the closest in the case library to category-default Recommendation status across the full prompt set. A 2.17 average ranking and 90.61% mention coverage put the brand inside the AI consideration set on almost every query. Recommendation rate, where the brand is the suggested choice in a commercial-intent answer, is the third tier and is the next horizon for the measurement programme.
Three Observations
Advisory Categories Reward Consistency over Spikes
The 16.1% to 18.1% share-of-voice movement over 11 weeks is a small absolute number, but the trajectory shape is the more important read. Stable upward over multiple weeks looks like authority to AI. Spiky upward looks like manipulation. In advisory categories where the buyer is in cross-checking mode by default, the shape of the trajectory may matter more than the headline number.
The Top-Two Positioning Is Where Recommendation Outcomes Start
A 2.17 average ranking position is not just “the brand is mentioned.” It is “the brand is inside the answer in a position where it gets quoted, paraphrased, or recommended.” That is the precondition for Recommendation tier outcomes. Programmes that report on mention rate alone miss this distinction.
90% Mention Coverage Is a Ceiling Number, Not a Target
This engagement got to 90.61% across 150 tracked prompts. That number is approaching the practical ceiling for any brand operating in a competitive category. Almost no brand should aim for 100%. Some prompts are not yours to win and chasing them produces low-ROI work. The right number to target is what you can hold against your competitive set on the priority prompts. This brand held it at the top.
What Was Not In Scope
The work explicitly excluded several practices. This matters in 2026 because Google’s May 15 spam-policy update on generative search formally classified most of them as spam.
- No paid placements with passing links. Any sponsored editorial carried rel=”sponsored” or rel=”nofollow”.
- No syndicated press release distribution with optimised anchor text.
- No anonymous Wikipedia editing on the brand’s behalf.
- No AI-generated content published at scale.
- No incentivised or coordinated reviews on platforms AI reads.
These are not stylistic preferences. They are the line between sustainable AI visibility work and tactics that are about to be audited out of the market.
In May we renamed our signature practice from “AI Citation Engineering” to “AI Citation Enablement”. The acronym (AICE) stayed, the framing changed. “Engineering” implies working on AI’s evaluation. “Enablement” describes working on the brand. The second framing is the only one I am comfortable defending in client engagements over the next two years.
Where To Start
If your brand operates in a high-trust advisory category and has not been benchmarked against the major AI platforms, that is the place to start. We run a complimentary AI Visibility Audit. It takes a week, produces a board-ready benchmark against your top competitors across all five major AI platforms, and surfaces the consistency patterns that matter most in advisory contexts. The audit is the diagnostic phase of the AI Visibility Operating System we build for enterprise CMOs.