What The PAVA Framework Engagement Looks Like In Knowledge-led Services.
An education-services client engaged us last quarter operating in a knowledge-led services category where AI platforms have moved aggressively into the early consideration set. Buyers were running queries like “best providers for [knowledge area]” and shortlisting from the AI answer before any direct outreach. The brand was inconsistently appearing in those answers and a smaller competitor with sharper category positioning was being named ahead of it.
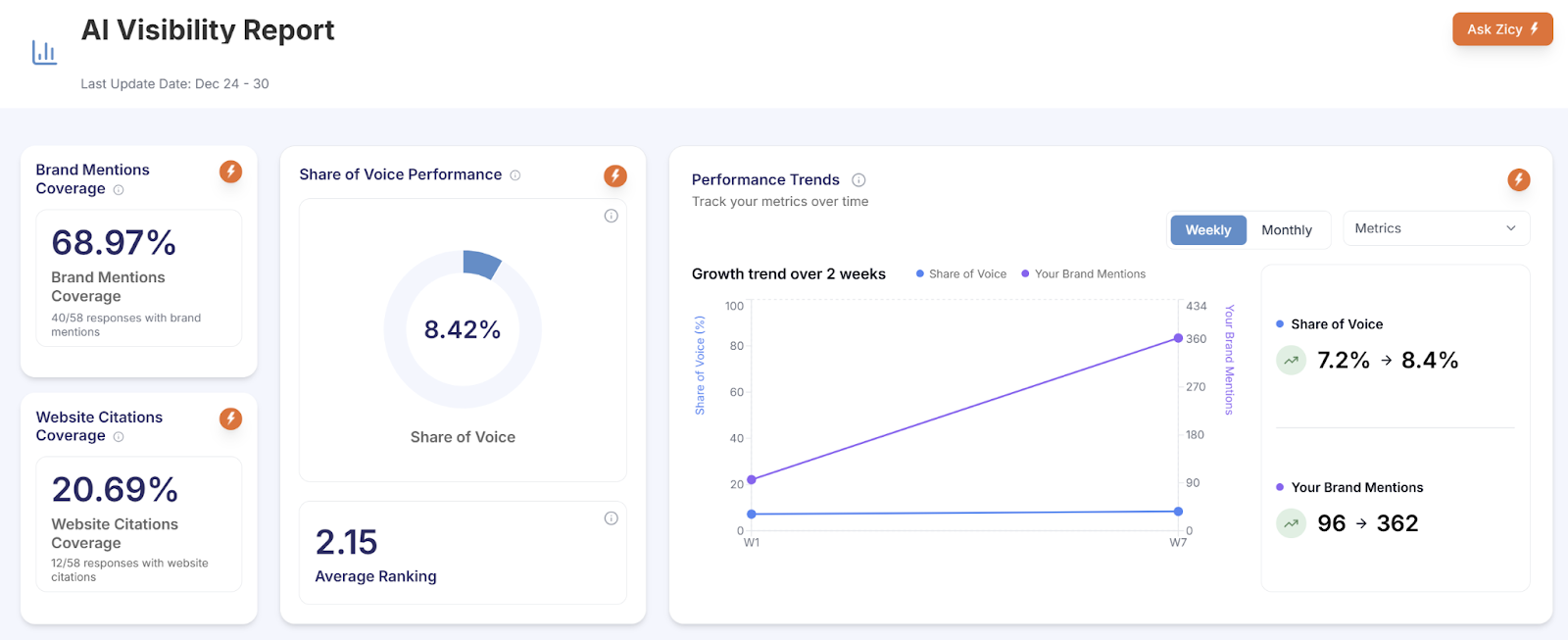
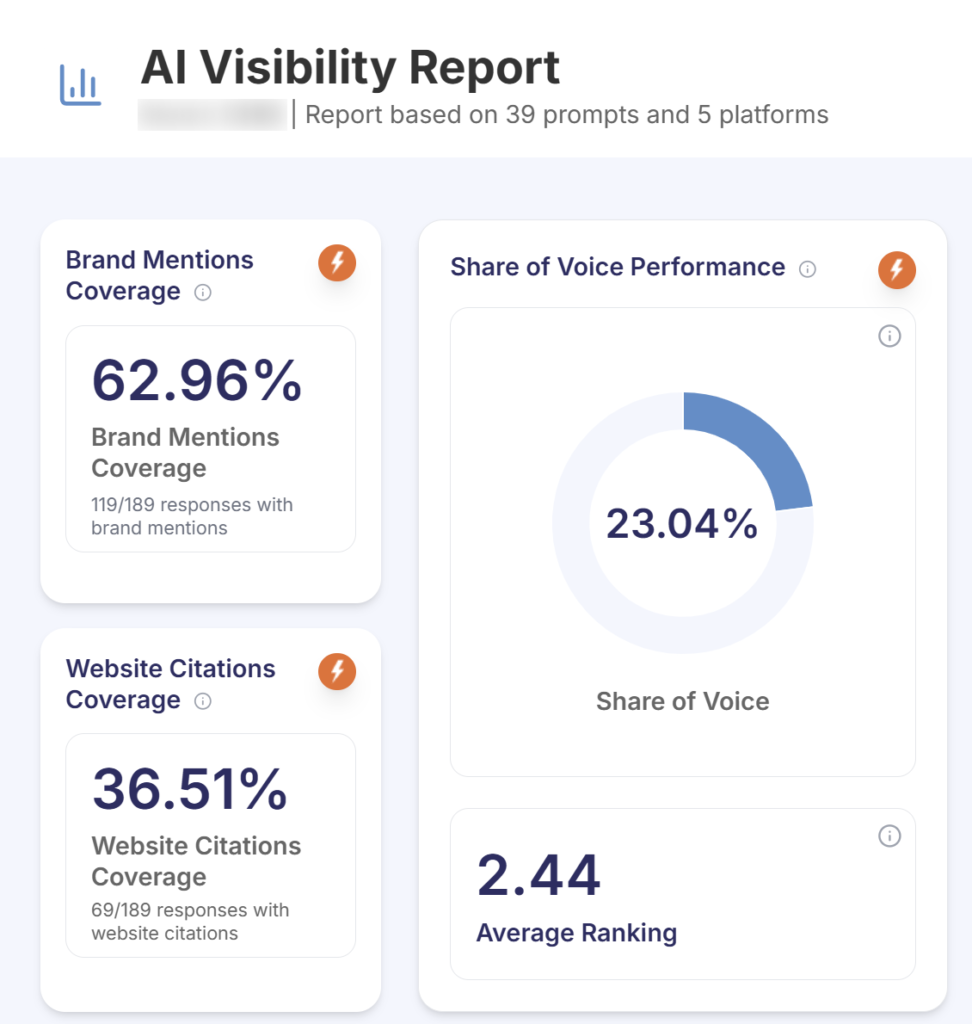
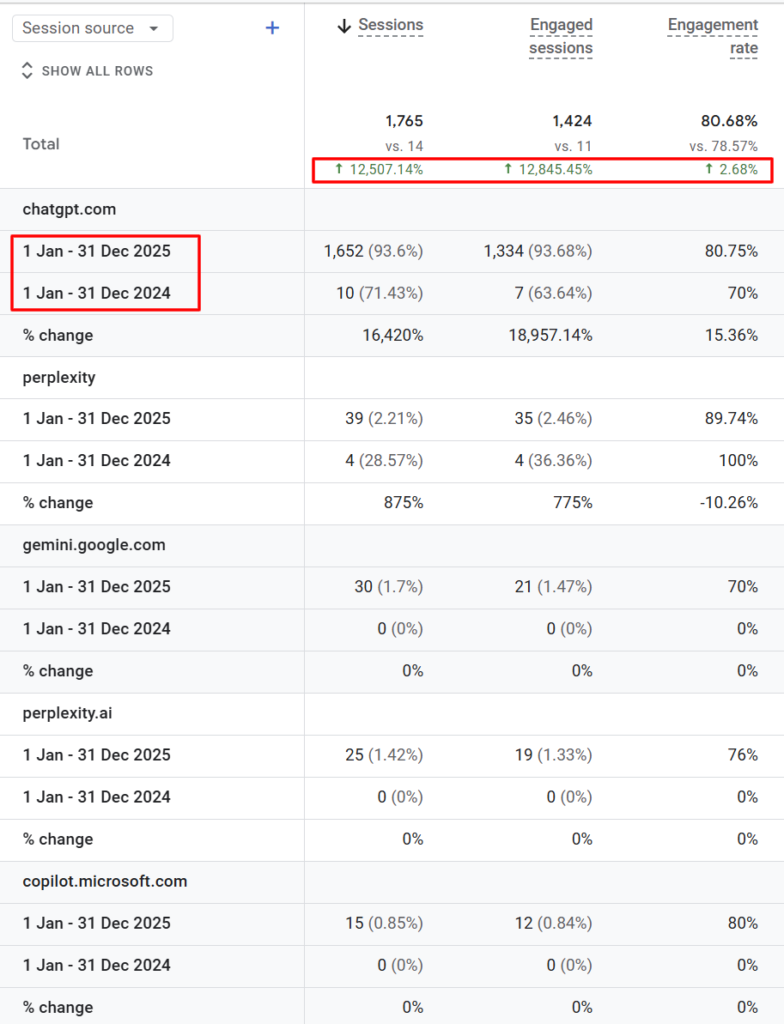
Across the engagement, the brand took the top share-of-voice position in the category at 23.04%, with 62.96% mention coverage and a 2.44 average AI ranking. AI-driven sessions grew 12,507% year over year on a small but real base.
Below is what the work involved, and what I would take from it.
The Starting Position
Knowledge-led services categories share a structural feature: the buyer is purchasing expertise and credibility. The first signal they reach for is the third-party citation, the comparison summary, the “who do you recommend” question. AI platforms are now answering all three before the buyer has visited any provider’s website.
For service brands in this category, that means the AI layer is shaping the consideration set from a position of near-total information asymmetry against the providers themselves. The provider often does not know they are being compared. They certainly do not know which competitors AI is naming.
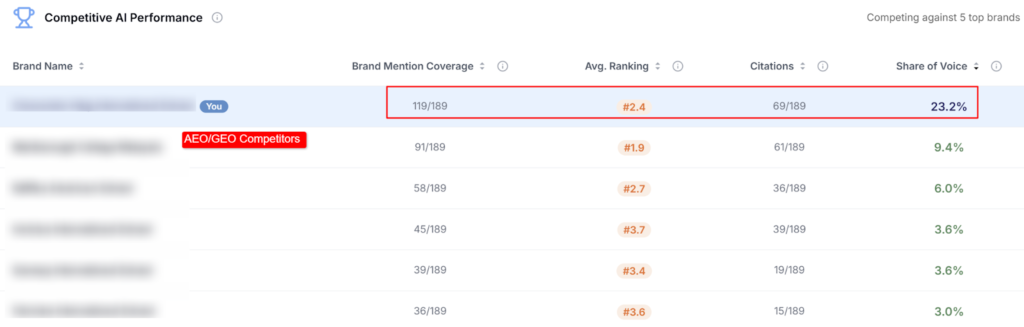
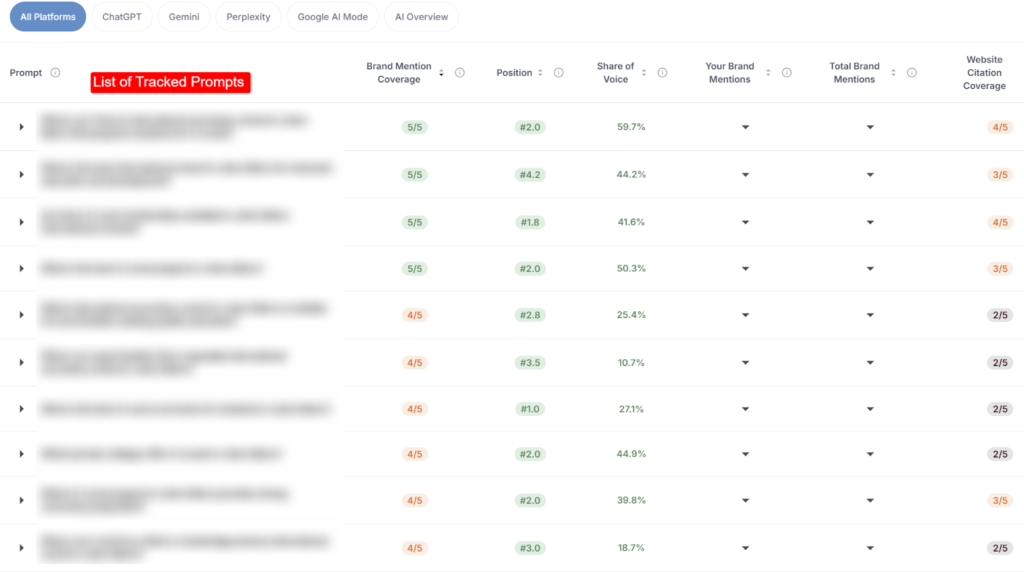
We baselined this brand across ChatGPT, Gemini, Perplexity, Google AI Overviews, and Google AI Mode. We mapped 39 real-world prompts the buyers actually run. We benchmarked against five competitors.
The picture: meaningful presence on some priority queries, complete absence on others, competitors getting named consistently in the absence gaps.
What The Work Involved
The engagement ran across all four pillars of the PAVA Framework: Presence, Authority, Visibility, Amplification. Each pillar addresses a question AI platforms appear to weigh before deciding whether to surface a brand in an answer.
-
PRESENCE. Entity integrity.
Service page descriptions were tightened for attribution clarity. The brand-entity signals AI systems rely on for identification were strengthened. Ambiguous phrasing that was leading to generic or competitor citations was removed. Schema deployment across organisation and educational service types. Canonical brand description aligned across LinkedIn, Crunchbase, and the relevant directories. Wikipedia work went through the standard contributor process with paid-contributor disclosure where the policy requires it. -
AUTHORITY. Earned editorial standing.
We mapped the third-party publications and category-defining outlets AI cites in this knowledge-led services category. We briefed the brand’s existing PR partner against that target list with angle briefs aligned to genuine editorial opportunities the firm could pursue on the merits of the work. Citation outcomes measured against each placement.This is what AI Citation Enablement looks like on the earned side. AICE is the discipline we run across all four PAVA pillars: making the brand’s expertise easier for AI to find, verify, and accurately attribute, on the brand’s own merits.
-
VISIBILITY. Content architecture.
We mapped the prompt universe, our term for the 39 high-intent commercial and comparison queries the brand’s buyers actually run. Prompt-level performance analysis surfaced prompts where the brand had strong rankings but weak mention coverage. Those gaps became the priority commissioning queue.Owned content was restructured into the formats AI retrieval systems extract most reliably: direct answers at the top of service pages, comparison tables for evaluation-stage queries, named methodology frameworks, and statistics sourced with publisher, sample, and year.
-
AMPLIFICATION. Sustained presence.
Continuous monitoring across all five named AI platforms. Visibility trends tracked over time rather than relying on snapshot reads. Ranking, mention, and citation deltas used to validate progress. Sentiment patterns across cited sources watched continuously.The compounding effect on this engagement was significant because the brand was building from a small base. AI-referred sessions grew over 12,507% year over year, and engaged sessions grew over 12,845%. From a small absolute starting point, but the trajectory is the read.
The Numbers
AI VISIBILITY METRICS:
- Brand mention coverage: 62.96%
- Citation rate: 36.51%
- Share of voice: 23.04% (#1 in category against five competitors)
- Average AI ranking position: 2.44
AI TRAFFIC GROWTH (YoY, GA4):
- AI-driven sessions: +12,507%
- Engaged AI sessions: +12,845%
- Dominant platform: ChatGPT, with incremental growth from Perplexity and Gemini
We measure outcomes against what we call the M-C-R stack: Mention, Citation, Recommendation. This engagement moved Mention coverage materially to 62.96% and put the brand at the top of the category on share of voice at 23.04%. The 2.44 average ranking position is approaching the Recommendation tier. Recommendation rate, where the brand is the suggested choice in a commercial-intent answer, is the third tier and the next horizon for the measurement programme.
The 12,507% YoY traffic number is real but worth interpreting carefully. The starting base was small. The growth is structural rather than absolute. The more durable read is the share-of-voice position. Becoming the #1 share-of-voice brand in a knowledge-led services category against five competitors is the structural moat. The traffic compounds from there.
Three Observations
Knowledge-led Services Categories Reward The Provider With The Clearest Definitional Positioning.
AI systems disambiguate competing service providers by reaching for the clearest entity signals. The provider whose category description, service positioning, and brand-entity signals are unambiguous gets cited preferentially. Most providers in these categories have positioning written for human persuasion, not AI extraction. The clarity audit was the highest-leverage early intervention.
The Gap Between Strong Ranking And Weak Mention Is A Fixable Problem.
On several priority prompts, the brand was ranking inside the AI answer but the brand mention coverage was weak. That is a content-clarity gap, not an authority gap. The brand was being represented but not named cleanly. Tightening attribution clarity on the relevant service pages closed the gap measurably. Most AI visibility programmes do not break out this distinction. They should.
Share Of Voice Is The Better Indicator Than Mention Rate In Competitive Categories.
This brand took 23.04% of category share of voice against five competitors. That is a categorical leadership signal. Mention rate alone could miss this if competitors are being mentioned even more frequently. The ratio against the competitive set is the read that matters.
What Was Not In Scope
The work explicitly excluded several practices. This matters in 2026 because Google’s May 15 spam-policy update on generative search formally classified most of them as spam.
- No paid placements with passing links. Any sponsored editorial carried rel=”sponsored” or rel=”nofollow”.
- No syndicated press release distribution with optimised anchor text.
- No anonymous Wikipedia editing on the brand’s behalf.
- No AI-generated content published at scale.
- No incentivised or coordinated reviews on platforms AI reads.
These are not stylistic preferences. They are the line between sustainable AI visibility work and tactics that are about to be audited out of the market.
In May we renamed our signature practice from “AI Citation Engineering” to “AI Citation Enablement”. The acronym (AICE) stayed, the framing changed. “Engineering” implies working on AI’s evaluation. “Enablement” describes working on the brand. The second framing is the only one I am comfortable defending in client engagements over the next two years.
Where To Start
If your brand operates in a knowledge-led services category and has not been benchmarked against the major AI platforms, that is the place to start. We run a complimentary AI Visibility Audit. It takes a week and produces a board-ready benchmark against your top competitors across all five major AI platforms, with the strong-ranking-but-weak-mention gap analysis surfaced explicitly. The audit is the diagnostic phase of the AI Visibility Operating System we build for enterprise CMOs.
DM me if that is useful.